VoxForge
VoxForge
The amount of speech audio required to improve the VoxForge Speaker Independent Acoustic Model for your voice depends on many things, however, the HTK manual says that a performance improvement should be observable with just 30 seconds of speech (around 20 utterances).
|
Note: the speech audio files you recorded in the How-to and Tutorial were recorded with a 48 kHz sampling rate at 16 bits per sample. The VoxForge Speaker Independent Acoustic Models we will use in this tutorial were trained with audio recorded at 8kHz:16-bit (we also have 16kHz:16-bits Acoustic Models - see the Nightly Builds directory on the VoxForge Repository). Because
of this,
you need to 'downsample' your speech audio files to 8kHz:16-bits and
then convert them to HTK '.mfc' files. For details on Acoustic Model Creation see this link. |
1. First, create a new directory called 'adapt' in your voxforge directory.
2. create a directory called 'wav' in your adapt directory.
3. create a file called 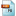 FilesToBeDownsampled in your 'adapt' directory.
FilesToBeDownsampled in your 'adapt' directory.
4.
copy the
 downsample.pl
script to your adapt directory (note that if you download this file,
you need to rename it to 'downsample.pl' - otherwise it will download
as 'downsample_pl.txt').
downsample.pl
script to your adapt directory (note that if you download this file,
you need to rename it to 'downsample.pl' - otherwise it will download
as 'downsample_pl.txt').
5. run the downsample.pl script as follows:
| $./downsample.pl FilesToBeDownsampled wav 48000 8000 |
6. Download the most current VoxForge Acoustic Model from the Nightly Builds directory, and put the following files in the new 'adapt' directory you just created: